
When launching our Talky videochat service almost two years ago there was one thing missing: the TURN server.
WebRTC creates peer-to-peer connections between browsers to transfer the audio and video data, but sometimes it needs a little help to establish a connection. The TURN server is the thing that helps here: it is deployed on the Internet and relays data for two clients that fail to establish a direct, P2P connection (thus avoiding the dreaded "black video" problem). TURN is generally considered one of the hard topics when people start doing WebRTC and crucial to running a successful service.
When I started at &yet back in March one of the first things I did was to add a TURN server. We choose the open-source restund server because it had proven to be mature and very easy to extend earlier. The rfc-5766-turn-server is another popular choice here, but the design and extensibility of restund was more appealing to us.
In response to adding a TURN server, the number of "black video" problems that users reported went down to almost zero. The exception were Firefox users and this turned out to be a Firefox bug which was fixed.
This worked for a while, but as Talky.io usage grew, we had an outage.
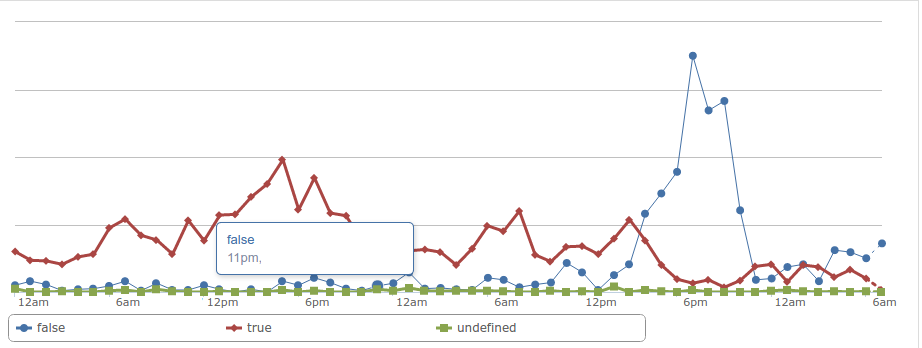
This was very noticeable in our metrics, but on the Operations side it was not noticed early enough. It turned out we had a too-hard limit on the maximum number of concurrent allocations and Chrome was keeping allocations around longer than required.
Now that our TURN server was moving from a research role to a production role we started looking very extensively into the operational aspects of running TURN servers. It is not as simple as "install it and you're done" so we would need to build or find monitoring and server management tools for restund.
Since you can only fix things that you can measure, we wrote a module that sends the load metrics from restund to InfluxDB. We monitor the number of allocations and currently active sessions, the bandwidth, and CPU usage, among other things. We have a nice dashboard which shows the load data, allowing us to figure out if there is a problem with a single look.
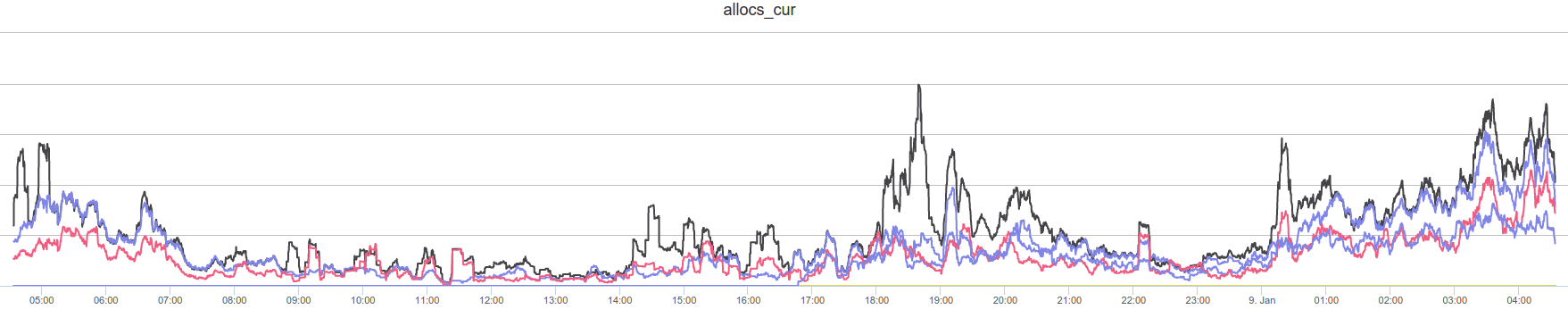
If we had visualized the data earlier, it would not have taken us long to report the aforementioned bug since the number of allocations is higher than one would expect for the number of clients.
Our monitoring also enables us to determine that a single instance of restund is very efficient - our instance is able to handle traffic in the order of 100 megabit per second almost exclusive in kernel mode. While this is impressive it does means there is not much room left for optimization, so we quickly needed to be able to scale horizontally in order to meet demand.
Scaling any network resource requires load balancing - and load balancing means you have to be able to start/stop any service as needed. Initially, adding or removing a TURN server required a restart of the signalmaster server which would have caused a disruption of the videochat service. With little effort we can push an updated TURN config to signalmaster which gives us the ability to change the TURN servers on the fly. That way, we can take a TURN server out of service, allowing it to be restarted once all users have switched to other servers.
Currently, that balancing is a simple random choice but it is trivial to employ a different strategy like figuring in the actual load from the metrics or the geographic location of the client. Together with an automated deployment of TURN servers using Ansible, we can scale in a matter a minutes.
Looking back, we've realized that this kind of operations infrastructure is one of the most important aspects of running a WebRTC service.
It's also the hardest to get right.
But after almost a year of experimentation, real-world trial and error, measurement and adjustment, we've become confident at quickly shaking out the kind of issues that plague those trying to run their own TURN servers.
If you're looking for help configuring your TURN servers, we'd be happy to talk. Feel free to reach out and we'll get back to you right away. You can also see more about our WebRTC offerings here and here.